
Le transport optimal numérique et ses applications
Dans cet article, Gabriel Peyré nous présente l’évolution historique du problème du « transport optimal ». Introduit par Monge au XVIIIe siècle, ce problème s’est transformé au fil du temps jusqu’à devenir un outil important de la science des données.
Gabriel Peyré
© APMEP Septembre 2019
⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅♦⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅
Le transport optimal de Monge
Gaspard Monge, en plus d’être un grand mathématicien, a participé activement à la Révolution française, et a créé l’École Polytechnique ainsi que l’École Normale Supérieure. Motivé par des applications militaires, il a formulé en 1781 le problème du transport optimal [7] : il s’est posé la question du calcul de la façon la plus économique de transporter de la terre entre deux endroits pour faire des remblais. Dans son texte original, il a fait l’hypothèse que le coût du déplacement d’une unité de masse est égal à la distance parcourue, mais on peut utiliser n’importe quel coût adapté au problème à résoudre.
Le problème de Monge
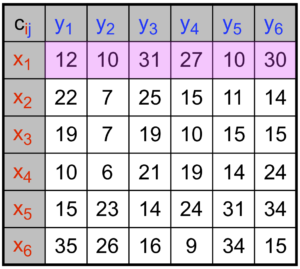
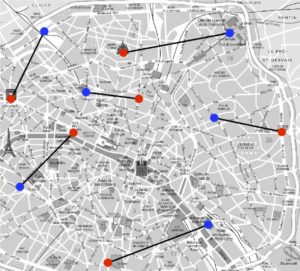
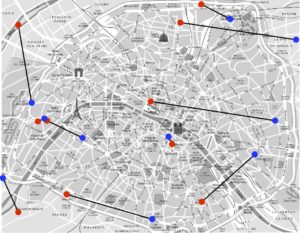
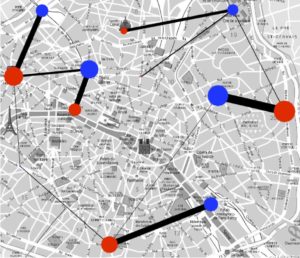
Pour illustrer le problème et sa formulation mathématique, intéressons-nous à la façon optimale de distribuer les croissants depuis les boulangeries vers les cafés, le matin dans Paris. Pour simplifier, nous allons supposer qu’il y a uniquement six boulangeries et cafés, que l’on peut voir à la figure 1 (les boulangeries sont en rouge et les cafés en bleu). On suppose que toutes les boulangeries produisent le même nombre de croissants et que tous les cafés demandent également ce même nombre de croissants.
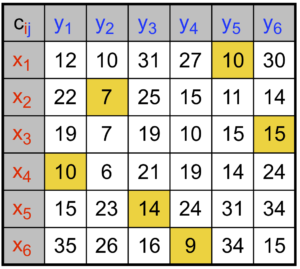
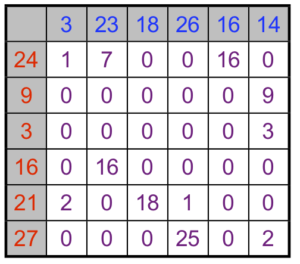
Le coût à minimiser est le temps total des trajets, et l’on note \(C_{{\color{red}i},{\color{blue}j}}\) le temps entre la boulangerie \({\color{red}i}\in \{1,\ \ldots,\ 6\}\) et le café \({\color{blue}j}\in \{1,\ \ldots,\ 6\}\). Par exemple, on a \(C_{{\color{red}3},{\color{blue}4}}=10\), ce qui signifie qu’il y a dix minutes de trajet entre la boulangerie numéro \({\color{red}3}\) et le café numéro \({\color{blue}4}\).
Afin de satisfaire la contrainte d’approvisionnement (que l’on appelle aussi la conservation de la masse), il faut que chaque boulangerie soit connectée à un et un seul café. Comme il y a le même nombre de boulangeries que de cafés, ceci implique que chaque café est également connecté à une et une seule boulangerie. On va noter \(\sigma : {\color{red}i}\in \{1,\ \ldots,\ 6\} \longmapsto {\color{blue}j}\in \{1,\ \ldots,\ 6\}\) un tel choix de connexions.
 |
 |
 |
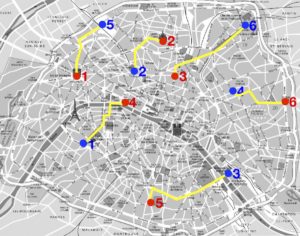 |
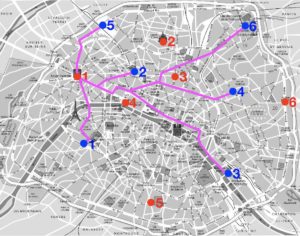
Les deux images de droite de la figure 1 illustrent l’exemple
\[\tag{1}
\sigma({\color{red}1})={\color{blue}5}, \ ;
\sigma({\color{red}2})={\color{blue}2}, \ ;
\sigma({\color{red}3})={\color{blue}6}, \ ;
\sigma({\color{red}4})={\color{blue}1}, \ ;
\sigma({\color{red}5})={\color{blue}3}, \ ;
\sigma({\color{red}6})={\color{blue}4}.\]
La contrainte de conservation de masse signifie que \(\sigma\) est une bijection de l’ensemble \(\{1,\ \ldots,\ 6\}\) dans lui-même. On dit aussi que \(\sigma\) est une permutation.
Le coût de transport associé à une telle bijection est la somme des coûts \(C_{{\color{red}i},\sigma({\color{red}i})}\) sélectionnés par la permutation \(\sigma\), c’est-à-dire
\[\tag{2}
\text{Coût}(\sigma) \stackrel{\mbox{def.}}{=}
C_{{\color{red}1},\sigma({\color{red}1})} +
C_{{\color{red}2},\sigma({\color{red}2})} +
C_{{\color{red}3},\sigma({\color{red}3})} +
C_{{\color{red}4},\sigma({\color{red}4})} +
C_{{\color{red}5},\sigma({\color{red}5})} +
C_{{\color{red}6},\sigma({\color{red}6})}.\]
Par exemple, pour la bijection (1) montrée à la figure 1, on obtient comme coût
\[C_{{\color{red}1},{\color{blue}5}} +
C_{{\color{red}2},{\color{blue}2}} +
C_{{\color{red}3},{\color{blue}6}} +
C_{{\color{red}4},{\color{blue}1}} +
C_{{\color{red}5},{\color{blue}3}} +
C_{{\color{red}6},{\color{blue}4}} =
10 + 7 + 15 + 10 + 14 + 9 = 65.\]
Le problème de Monge consiste à chercher une permutation \(\sigma\) qui a le coût minimum, c’est-à-dire résoudre le problème d’optimisation
\[\tag{3}\underset{\sigma \in \Sigma_6}{\min} \text{Coût}(\sigma),\]
où l’on a noté \(\Sigma_6\) l’ensemble des permutations de l’ensemble \( \{1,\ \ldots,\ 6 \} \).
 Coût=64 |
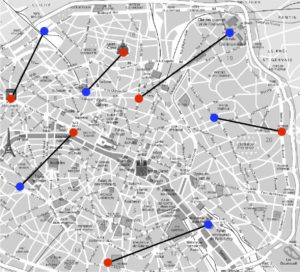 Coût=65 |
 Coût=66 |
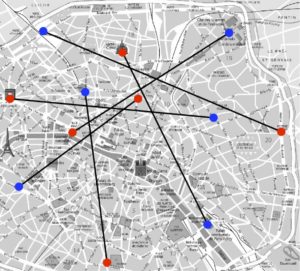 Coût=152 |
La figure 2 montre que la permutation (1) n’est pas la meilleure : il existe par exemple une autre permutation qui a un coût de \(64\). Mais est-ce la meilleure ? Il se trouve que oui, on peut en effet tester sur un ordinateur toutes les permutations de \(\{1,\ \ldots,\ 6\}\) et calculer leur coût. Combien y a-t-il de permutations au total ? Pour effectuer ce dénombrement, on voit qu’il y a six choix d’affectation possible de \({\color{red}1}\) à \(\sigma({\color{red}1}) \in
\{{\color{blue}1,\ \ldots,\ 6}\}\), puis cinq choix possibles pour affecter \({\color{red}2}\) à \(\sigma({\color{red}2})\in\{{\color{blue}1,\ \ldots,\ 6}\}\smallsetminus\{\sigma({\color{red}1})\}\), et ainsi de suite. Le nombre total de possibilités est donc \(6 \times 5 \times 4
\times 3 \times 2 \times 1 = 720\) (que l’on note \(6 !\)). Si l’on considère un nombre \(n\) de boulangeries, alors le nombre de permutations à tester pour trouver la meilleure est \(n ! =n \times (n-1) \times \cdots \times 2 \times
1\). Ce nombre croît extrêmement vite avec \(n\), par exemple \(70 ! \approx{1,198}
\times 10^{100}\), à comparer avec les \(10^{11}\) neurones dans le cerveau et les \(10^{79}\) atomes dans l’Univers. Cette stratégie de recherche exhaustive n’est donc possible que pour de toute petites valeurs de \(n\).
En 1D et 2D
Il aura fallu près de 200 ans pour que des idées nouvelles émergent pour calculer efficacement un transport optimal \(\sigma\) même pour des grandes valeurs de \(n\). Avant d’expliquer ces avancées mathématiques, commençons par un cas dans lequel le transport optimal se calcule facilement.
Le cas le plus élémentaire est lorsque les points à apparier sont le long d’un axe 1D, par exemple si les cafés et les boulangeries sont situés le long d’une ligne de métro. Il faut également que le coût \(C_{{\color{red}i},{\color{blue}j}}\) soit la distance le long de cet axe (par exemple le temps de trajet en métro entre les stations).
On se place à gauche de tous les points en jeu et on parcourt la ligne de métro de gauche à droite. Le premier point rouge est associé avec le premier point bleu, le deuxième point rouge avec le deuxième point bleu, etc.
Ce procédé est illustré à la figure 3.
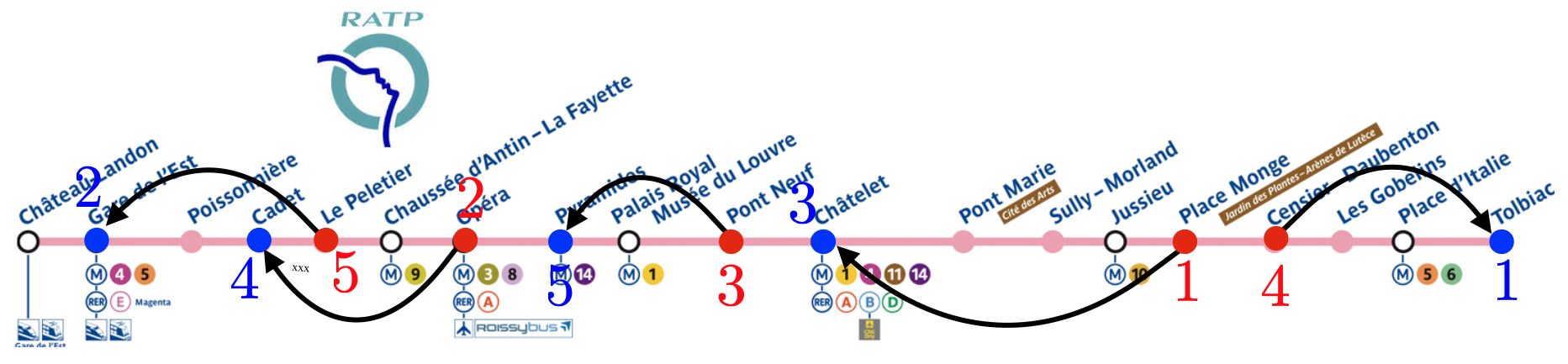
Figure 3 : Le transport optimal en 1D le long d’une ligne de métro. La bijection optimale est \(\sigma : ({\color{red}{1,2,3,4,5}}) \longmapsto ({\color{blue}{3,4,5,1,2}})\). ↩
Le temps de calcul nécessaire pour calculer le transport optimal en métro est donc le temps nécessaire pour classer les indices. L’algorithme le plus simple pour effectuer un classement est celui utilisé habituellement pour trier un jeu de \(n\) cartes : il s’agit du tri par insertion, qui insère itérativement chaque carte à sa place par rapport aux cartes déjà classées. Il effectue \(\dfrac{n(n-1)}{2\mathstrut}\) comparaisons. Pour \(n=70\), ceci nécessite donc seulement 2415 opérations, ce qui rend la méthode utilisable, au contraire de la recherche exhaustive de toutes les \(n !\) permutations.
On dispose d’algorithmes encore plus rapides (par exemple le tri fusion), qui effectuent de l’ordre de \(n \log(n)\) opérations, et donc pour \(n = 70\), de telles méthodes nécessitent moins de 1000 opérations.
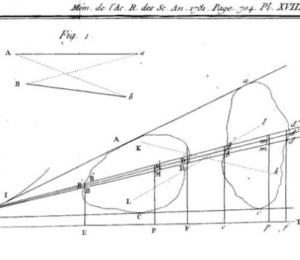
Malheureusement, il n’est plus possible d’utiliser cette technique de classement dans des cas plus généraux. Pour des points en dimension 2, si on prend comme coût \(C_{{\color{red}i},\sigma({\color{red}i})}\) la distance euclidienne (la distance en vol d’oiseau) entre les points, alors Gaspard Monge a montré dans son papier original (voir la figure 4, à gauche) qu’un transport optimal ne peut pas contenir de croisement. Par exemple, comme le montre la figure 4 (à droite), si l’on trace tous les segments entre les points \({\color{red}i}\mapsto {\color{blue}j}= \sigma({\color{red}i})\) que l’on relie par la bijection définie par un \(\sigma\) optimal, ceux-ci ne se croisent jamais.
 |
 |
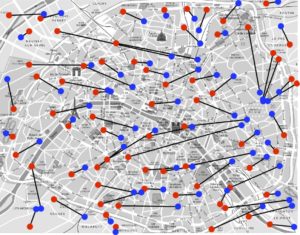 |
Cette observation géométrique n’est cependant pas suffisante pour calculer un transport optimal en 2D : il existe en effet beaucoup de permutations \(\sigma\) telles que les segments associés ne se croisent pas.
Il va falloir analyser de façon plus fine la structure des permutations optimales afin de pouvoir les calculer de façon efficace.
Nous allons maintenant voir comment Leonid Kantorovitch a reformulé le problème de Monge afin d’y parvenir.
Le transport optimal de Kantorovitch
Leonid Kantorovitch est un mathématicien et économiste soviétique qui a révolutionné la théorie du transport optimal pendant les années 40. Ses recherches sont issues de considérations pratiques qui l’ont occupé avant et après la seconde guerre mondiale. Il y a joué un rôle important pour assurer une distribution optimale des ressources, en particulier durant le siège de Léningrad.
Il a par la même occasion participé au développement de l’optimisation moderne, laquelle a eu un impact énorme dans de très nombreux domaines appliqués. Il a ainsi obtenu en 1975 le prix Nobel d’économie, car les premières applications (mais certainement pas les seules !) de sa théorie se sont manifestées dans ce domaine.
Le problème de Kantorovitch
L’idée centrale de Kantorovitch [6] est de modifier le problème de Monge en remplaçant l’ensemble des permutations par un ensemble plus grand mais plus simple. Tout d’abord on remarque que l’on peut représenter une permutation \(\sigma \in \Sigma_n\) à l’aide d’une matrice de permutation \(P\) qui est une matrice binaire (remplie de 0 et de 1) de taille \(n \times n\) telle que \(P_{{\color{red}i},{\color{blue}j}} = 0\) sauf si \({\color{blue}j}=\sigma({\color{red}i})\) auquel cas \(P_{{\color{red}i},\sigma({\color{red}i})} = 1\). Par exemple, pour \(n=3\) points, les permutations \(({\color{red}{1,2,3}}) \mapsto ({\color{blue}{1,2,3}})\) (l’identité), \(({\color{red}{1,2,3}}) \mapsto
({\color{blue}{3,2,1}})\) et \(({\color{red}{1,2,3}}) \mapsto ({\color{blue}{2,1,3}})\) sont respectivement représentées par les matrices de taille \(3 \times 3\)
\[\begin{pmatrix} 1& 0 & 0 \\ 0& 1& 0 \\ 0& 0& 1 \end{pmatrix}, \quad
\begin{pmatrix} 0& 0& 1 \\ 0& 1& 0 \\ 1& 0& 0 \end{pmatrix} \quad \text{et} \quad
\begin{pmatrix} 0& 1& 0 \\ 1& 0& 0 \\ 0& 0& 1 \end{pmatrix}.\]
Dans la suite, on note \(\mathcal{P}_n\) l’ensemble des \(n !\) matrices de permutation de taille \(n \times n\).
Comme la matrice est binaire, avec seulement \(n\) éléments non nuls égaux à 1, on peut remplacer la somme de \(n\) termes qui apparaît dans \(\text{Coût}(\sigma)\) défini en par une somme sur l’ensemble des \(n \times n\) indices \(({\color{red}i},{\color{blue}j})\), c’est-à-dire que si \(P\) est la matrice de permutation associée à \(\sigma\), on a
\[\text{Coût}(\sigma) = \sum_{{\color{red}i}=1}^n \sum_{{\color{blue}j}=1}^n P_{{\color{red}i},{\color{blue}j}} C_{{\color{red}i},{\color{blue}j}}.\]
On peut ainsi remplacer le problème de Monge (3) par le problème équivalent
\[\tag{4}
\underset{P \in \mathcal{P}_n}{\min} \sum_{{\color{red}i}=1}^n \sum_{{\color{blue}j}=1}^n P_{{\color{red}i},{\color{blue}j}} C_{{\color{red}i},{\color{blue}j}}.\]
Le génie de Kantorovitch a été de remarquer que l’on peut remplacer l’ensemble discret \(\mathcal{P}_n\) (c’est-à-dire composé d’un ensemble fini, mais très grand, de \(n !\) matrices) par un ensemble « continu » (donc en particulier infini) mais plus simple. On remarque en effet que les matrices de permutation de \(\mathcal{P}_n\) sont exactement les matrices qui ont un et un seul 1 le long de chaque ligne et de chaque colonne. Ceci peut aussi s’exprimer comme le fait qu’une matrice de permutation est une matrice binaire dont la somme de chaque ligne et de chaque colonne vaut 1, c’est-à-dire
\[\mathcal{P}_n = \left\{ P \in \{0,1\}^{n \times n} \ |\ \forall \, {\color{red}i}, \sum_{{\color{blue}j}} P_{{\color{red}i},{\color{blue}j}}=1, \forall \, {\color{blue}j}, \sum_{{\color{red}i}} P_{{\color{red}i},{\color{blue}j}}=1 \right\}.\]
Ce qui rend cet ensemble très compliqué, c’est la contrainte binaire, c’est-à-dire que ces matrices sont contraintes à être dans \(\{0,1\}^{n \times
n}\). Kantorovitch propose alors de « relaxer » cette contrainte en supposant simplement que les entrées de \(P\) sont entre \(0\) et \(1\). Ceci définit un ensemble plus grand, l’ensemble des matrices bistochastiques
\[\tag{5}
\mathcal{B}_n \stackrel{\mbox{def.}}{=}
\left\{ P \in [0,1]^{n \times n} \ |\ \forall \, {\color{red}i}, \sum_{{\color{blue}j}} P_{{\color{red}i},{\color{blue}j}}=1, \forall \, {\color{blue}j}, \sum_{{\color{red}i}} P_{{\color{red}i},{\color{blue}j}}=1 \right\}.\]
Le problème de Kantorovitch s’obtient en effectuant ce remplacement dans , afin de résoudre
\[\tag{6}\underset{P \in \mathcal{B}_n}{\min}
\sum_{{\color{red}i}=1}^n \sum_{{\color{blue}j}=1}^n P_{{\color{red}i},{\color{blue}j}} C_{{\color{red}i},{\color{blue}j}}.\]
L’immense avantage du problème de Kantorovitch (6) par rapport à celui de Monge (4) est que l’ensemble des matrices bistochastiques est convexe, c’est-à-dire que si l’on considère deux matrices bistochastiques \(P,\ Q \in \mathcal{B}_n\), alors \(tP +
(1-t)Q \in \mathcal{B}_n\) pour tout \(t\in[0;1]\) est encore bistochastique. Ceci n’est pas vrai pour les matrices de permutation, puisque la moyenne de deux matrices binaires \((P,Q)\) n’est pas binaire (sauf bien sûr si \(P=Q\)). Cette convexité est la clef pour le développement d’algorithmes efficaces.
Cette nouvelle formulation a en effet pu bénéficier d’une deuxième révolution initiée par George Dantzig [4], qui, à la même époque, a proposé l’algorithme du simplexe. Celui-ci permet de résoudre efficacement une certaine classe de problèmes d’optimisation convexe : les problèmes de programmation linéaire, dont (6) est un cas particulier. Dans le cas du problème de Kantorovitch, il existe en effet un algorithme du simplexe qui a une complexité de l’ordre de \(n^3\) opérations, ce qui permet de faire des calculs pour de grands \(n\), de l’ordre de plusieurs milliers.
L’équivalence Monge–Kantorovitch
L’ensemble des matrices bistochastiques est plus grand que celui des matrices de permutations, \(\mathcal{P}_n \subset \mathcal{B}_n\), de sorte que l’on a l’inégalité
\[\tag{7}
\underset{P \in \mathcal{B}_n}{\min}
\sum_{{\color{red}i}=1}^n \sum_{{\color{blue}j}=1}^n P_{{\color{red}i},{\color{blue}j}} C_{{\color{red}i},{\color{blue}j}}
\leq
\underset{P \in \mathcal{P}_n}{\min}
\sum_{{\color{red}i}=1}^n \sum_{{\color{blue}j}=1}^n P_{{\color{red}i},{\color{blue}j}} C_{{\color{red}i},{\color{blue}j}}\]
entre les problèmes de Kantorovitch et de Monge. Mais de façon à première vue surprenante, un théorème fondamental dû à George Birkhoff et à John von Neumann [2, 11] assure qu’en fait il y a égalité entre les valeurs de ces deux minimisations. En effet, ce théorème montre qu’il existe toujours une matrice solution du problème de Kantorovitch qui est une matrice de permutation, de sorte qu’elle est aussi solution du problème de Monge. Attention cependant, en général il n’y a pas unicité des solutions de ces problèmes : il peut exister une matrice bistochastique solution du problème de Kantorovitch qui n’est pas une permutation.
La conjonction de deux avancées spectaculaires, dues à Kantorovitch et à Dantzig, a permis de rendre le transport optimal applicable à des problèmes de grande taille, puisque l’algorithme du simplexe permet de résoudre en pratique ces problèmes.
Le cas pondéré
Outre son intérêt pratique, la formulation de Kantorovitch a aussi permis de généraliser le problème initial de Monge, en donnant le bon cadre pour le formaliser et l’étudier mathématiquement. En effet, le problème de Monge est très limité. Que se passe-t-il par exemple s’il n’y pas le même nombre \(n\) de cafés et \(m\) de boulangeries ? Le problème initial (3) n’a pas de solution, car on ne peut pas mettre en bijection deux ensembles de tailles différentes. Le bon concept n’est pas le nombre de boulangeries et de cafés, mais plutôt les distributions \(({\color{red}{a_1,\ \ldots,\ a_n}})\) de production (associées aux boulangeries) et les distributions \(({\color{blue}{b_1,\ \ldots,\ b_m}})\) de consommation des cafés.
Par exemple, si la première boulangerie produit 45 croissants par jour, on prendra \({\color{red}a_1} =45\), de même \({\color{blue}b_3} = 34\) signifie que le 3 café consomme 34 croissants par jour.
Dans le cas initialement considéré, où \(n=m\), toutes les quantités \({\color{red}a_i}\) et \({\color{blue}b_j}\) sont égales à 1. Mais dans de nombreux cas concrets, ces quantités sont quelconques. Ces quantités doivent être positives, et vérifier
\[{\color{red}{a_1+\cdots+a_n}} = {\color{blue}{b_1 + \cdots + b_m}},\]
de sorte qu’il y ait autant de production que de consommation. La construction de Kantorovitch s’adapte naturellement à ce cas de distributions générales, en remplaçant les matrices bistochastiques (5) par des matrices de « couplage » qui satisfont la contrainte de conservation de la masse
\[\mathcal{B}({\color{red}a},{\color{blue}b})\stackrel{\mbox{def.}}{=}
\left\{ P \in \mathbb{R}_+^{n \times m} \ ;|\ ; \forall \, {\color{red}i}, \sum_{{\color{blue}j}} P_{{\color{red}i},{\color{blue}j}}={\color{red}a_i}, \forall \, {\color{blue}j}, \sum_{{\color{red}i}} P_{{\color{red}i},{\color{blue}j}}= {\color{blue}b_j} \right\}.\]
Dans le cas initial où \(n=m\) et \({\color{red}a_i}={\color{blue}b_j}=1\), alors \(\mathcal{B}({\color{red}a},{\color{blue}b}) = \mathcal{B}_n\) et l’on retrouve des matrices bistochastiques. Dans le cas général, à chaque fois qu’une entrée \(P_{{\color{red}i},{\color{blue}j}}\) est non-nulle, ceci signifie que l’on transfère de la « masse » (ici une certaine quantité de croissants) entre \({\color{red}i}\) et \({\color{blue}j}\). Comme le montre la figure 5, on peut visualiser de différentes façons une telle matrice \(P\) couplant deux distributions \(({\color{red}a},{\color{blue}b})\).
 (a) matrice |
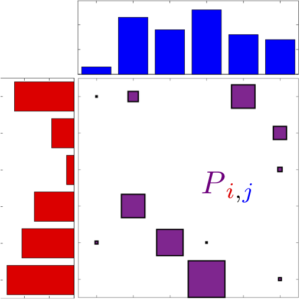 (b) histogrammes |
 (c) segments |
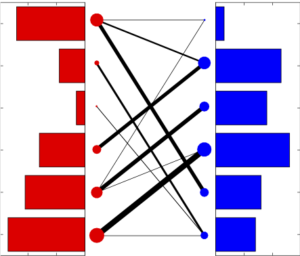 (d) graphe biparti |
Contrairement au cas des matrices bistochastiques, pour lequel il y a toujours une solution qui est une permutation, ici un couplage optimal \(\mathcal{B}({\color{red}a},{\color{blue}b})\) peut avoir plus d’une seule entrée non-nulle \(P_{{\color{red}i},{\color{blue}j}}\) le long d’une ligne indexée par \({\color{red}i}\) (voir la figure 5). Ceci signifie que cette boulangerie \({\color{red}i}\) est connectée à plusieurs cafés, de sorte que sa production est alors séparée en plusieurs lots de croissants distribués, tout en satisfaisant la contrainte de conservation de la masse \(\sum_{{\color{blue}j}} P_{{\color{red}i},{\color{blue}j}}={\color{red}a_i}\).
Le problème de Kantorovitch qui généralise (6) s’écrit alors
\[\tag{8}
\underset{P \in \mathcal{B}({\color{red}a},{\color{blue}b})}{\min}
\sum_{{\color{red}i}=1}^n \sum_{{\color{blue}j}=1}^m P_{{\color{red}i},{\color{blue}j}} C_{{\color{red}i},{\color{blue}j}}\]
ce qui signifie que l’on doit payer un coût \(C_{{\color{red}i},{\color{blue}j}}\) à chaque fois que l’on transfère une unité de masse entre \({\color{red}i}\) et \({\color{blue}j}\). Tout comme le problème original , on peut le résoudre de façon efficace avec l’algorithme du simplexe. La figure 5 montre un exemple de couplage optimal.
Les applications
Bien que les motivations initiales de Monge et Kantorovitch aient été respectivement militaires et économiques, le transport optimal a trouvé d’innombrables applications, à la fois théoriques et concrètes. Sur le plan mathématique, on peut considérer des distributions « continues » de masses, en quelque sorte la limite quand le nombre de points \(n\) tend vers l’infini. Ceci permet de définir le problème de transport entre des mesures de probabilités quelconques. Ce point de vue théorique est extrêmement fructueux, et c’est le mathématicien français Yann Brenier qui a le premier montré l’équivalence dans le cadre continu des formulations de Monge et de Kantorovitch [3]. Ces travaux pionniers ont montré la connexion entre le problème de transport et les équations aux dérivées partielles, et ont débouché, entre autres, sur les médailles Fields de Cédric Villani (2010) et Alessio Figalli (2018).
Le transport optimal est depuis peu au cœur de problématiques plus appliquées en sciences des données, en particulier pour résoudre des problèmes en traitement d’image et en apprentissage machine.
La première idée, la plus immédiate, est d’utiliser la bijection \(\sigma\) afin de transformer des données, par exemple des images. Dans ce cas, on considère les pixels \(({\color{red}x_i})_{{\color{red}i}=1}^n\) et \(({\color{blue}y_j})_{{\color{blue}j}=1}^n\) de deux images couleur. Chaque pixel \({\color{red}x_i}, {\color{blue}y_j} \in \mathbb{R}^3\) est un vecteur de dimension 3, qui représente les intensités de chacune des trois couleurs élémentaires, rouge, vert et bleu. Afin de changer les couleurs de la première image, et lui imposer la palette de la deuxième image, on calcule le transport \(\sigma\) pour la matrice de coût \(C_{{\color{red}i},{\color{blue}j}} = \| {\color{red}x_i} –
{\color{blue}y_j} \|^2\) (c’est-à-dire le carré de la norme euclidienne dans \(\mathbb{R}^3\)), c’est-à-dire le carré de la distance euclidienne entre les pixels. L’image avec les couleurs modifiées est \((y_{\sigma({\color{red}i})})_{{\color{red}i}=1}^n\), c’est-à-dire que l’on remplace dans la première image le pixel \({\color{red}x_i}\) par le pixel \(y_{\sigma({\color{red}i})}\). Cette image ressemble à la première, mais a la palette de couleurs de la deuxième image.
La figure 6 illustre ce procédé pour imposer la palette de couleurs de Picasso à un tableau de Cézanne.
 \(({\color{red}x_i})_{{\color{red}i}=1}^n\) 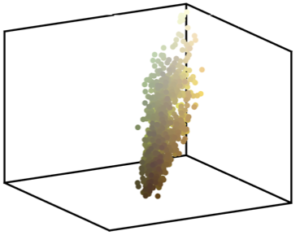 |
 \(({\color{blue}y_j})_{{\color{blue}j}=1}^n\) 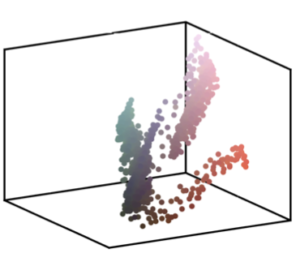 |
 \((y_{\sigma({\color{red}i})})_{{\color{red}i}=1}^n\) |
On peut également utiliser le transport optimal pour des problèmes plus difficiles, en n’utilisant que de façon indirecte la bijection \(\sigma\) ou bien la matrice de couplage optimal \(P \in \mathcal{B}({\color{red}a},{\color{blue}b})\). L’idée centrale est que la quantité associée à un couplage optimal \(P\) solution de
\[W({\color{red}a},{\color{blue}b})\stackrel{\mbox{def.}}{=} \sum_{i,j} P_{{\color{red}i},{\color{blue}j}} C_{{\color{red}i},{\color{blue}j}}\]
définit en quelque sorte l’effort nécessaire pour déplacer la masse de la distribution \({\color{red}a}\) vers la distribution \({\color{blue}b}\). Elle permet donc de quantifier combien ces deux distributions sont « proches ».
Par exemple, si \(C_{{\color{red}i},{\color{blue}j}} =
\|{\color{red}x_i} – {\color{blue}y_j}\|^2\) est le carré de la distance euclidienne entre des points, alors la quantité \(W({\color{red}a},{\color{blue}b})^{\textstyle\frac{1}{2}}\) est une distance entre les distributions, en particulier elle vérifie \(W({\color{red}a},{\color{blue}b})=0\) si et seulement si \({\color{red}a}={\color{blue}b}\), et elle vérifie l’inégalité triangulaire. Ces propriétés sont très importantes pour permettre d’appliquer le transport à des problèmes pratiques.

Figure 7 : Exemple d’interpolation barycentrique entre des formes 3D, obtenu en minimisant (9). ↩
Un exemple typique d’application de cette quantité \(W\) consiste à calculer des barycentres entre des distributions [1]. La figure 7 montre un exemple où l’on considère trois distributions \(a,b,c\) (montrées aux trois sommets du triangles) qui sont des distributions uniformes de masse à l’intérieur de formes 3D (c’est-à-dire que la masse \(a_i\) associée au \(i\)-ème point est 0 à l’extérieur de la première forme et prend une valeur constante à l’intérieur).
On calcule un barycentre pondéré de ces trois distributions en imitant le fait que dans un espace euclidien, le barycentre pondéré \(r\) de trois points \(x,y,z\) minimise la somme des distances au carré
\[\underset{r}{\min}\{\alpha \|x-r\|^2 + \beta \|y-r\|^2 + \gamma \|z-r\|^2\},\]
où les poids \((\alpha,\beta,\gamma)\) sont les pondérations du barycentre, qui sont des réels positifs tels que \(\alpha+\beta+\gamma=1\).
Le barycentre pondéré \(d\) de \((a,b,c)\) minimise ainsi la somme pondérée de distances de transport optimal
\[\label{eq-bary}
\underset{d}{\min} \{\alpha W(a,d) + \beta W(b,d) + \gamma W(c,d)\}.\]
En modifiant les poids \((\alpha,\beta,\gamma)\), on modifie la forme obtenue en se déplaçant à l’intérieur d’un triangle de transport optimal.
On peut utiliser cette distance \(W\) pour bien d’autres applications où l’on doit comparer des distributions de probabilité. C’est le cas en apprentissage machine, par exemple pour comparer des textes à l’aide des distributions des mots qui les composent. La figure 8 illustre les histogrammes d’apparition des mots pour deux textes, où la taille des lettres du mot \({\color{red}i}\) est proportionnelle à la masse \({\color{red}a}_{\color{red}i}\). Une question difficile dans ce cas est de savoir quelle matrice de coût \(C_{{\color{red}i},{\color{blue}j}}\) utiliser entre deux mots \(({\color{red}i},{\color{blue}j})\). Il s’agit d’un travail de linguistique (caractériser la proximité sémantique entre des mots du langage), que l’on peut chercher à résoudre en même temps que le transport optimal [5].
 |
 |
Conclusions
Le transport optimal a connu de nombreuses révolutions. Sous l’impulsion de mathématiciens tels que Monge, Kantorovitch, Dantzig et Brenier, il est progressivement devenu un outil théorique et numérique fondamental.
Il est maintenant au cœur de questions importantes en science des données pour modéliser, résoudre numériquement et analyser théoriquement les problèmes de l’apprentissage machine. Les opportunités pour développer de nouvelles théories et des algorithmes performants sont immenses.
Pour plus d’informations sur les aspects théoriques du transport optimal, on pourra consulter les livres [9, 10]. Les aspects numériques et applicatifs sont couverts dans le livre [8].
Remerciements
Je tiens à remercier Vincent Beck, Gwenn Guichaoua et Marie-Noëlle Peyré pour leurs relectures attentives.
Références
-
Martial Agueh et Guillaume Carlier. « Barycenters in the Wasserstein space ». In : SIAM Journal on Mathematical Analysis 43.2 (2011), p. 904-924. ↩
-
Garrett Birkhoff. « Tres observaciones sobre el algebra lineal ». In : Universidad Nacional de Tucumán Revista Series A 5 (1946), p. 147-151. ↩
-
Yann Brenier. « Polar factorization and monotone rearrangement of vector-valued functions ». In : Communications on Pure and Applied Mathematics 44.4 (1991), p. 375-417. ↩
-
George B. Dantzig. « Application of the simplex method to a transportation problem ». In : Activity Analysis of Production and Allocation 13 (1951), p. 359-373. ↩
-
Gao Huang et al. « Supervised word mover’s distance ». In : Advances in Neural Information Processing Systems. 2016, p. 4862-4870. ↩
-
Leonid Kantorovich. « On the transfer of masses ». Russe. In : Doklady Akademii Nauk 37.2 (1942). (Translated in Management Science, Vol. 5, pp. 1–4, 1959), p. 227-229. ↩
-
Gaspard Monge. « Mémoire sur la théorie des déblais et des remblais ». In : Histoire de l’Académie Royale des Sciences (1781), p. 666-704. ↩
-
Gabriel Peyré et Marco Cuturi. « Computational Optimal Transport ». In : Foundations and Trends in Machine Learning 11.5–6 (2019), p. 355-607. ↩
-
Filippo Santambrogio. Optimal transport for applied mathematicians. Birkhauser, 2015. ↩
-
Cédric Villani. Topics in Optimal Transportation. Graduate Studies in Mathematics Series. American Mathematical Society, 2003. ISBN : 9780821833124. ↩
-
John Von Neumann. « A certain zero-sum two-person game equivalent to the optimal assignment problem ». In : Contributions to the Theory of Games 2 (1953), p. 5-12. ↩
⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅♦⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅
Gabriel Peyré est directeur de recherche au CNRS ; ses domaines de recherche gravitent autour du traitement du signal et de la science des données.