
Comprendre la dérive génétique
à l’aide de la simulation
Au fil des expériences, Jean-Louis Marcia et ses collègues de SVT ont pu constater que la simulation permettait aux lycéens de mieux comprendre les phénomènes liés à la dérive génétique. C’est pourquoi il a conçu des activités pouvant être suivies comme un fil rouge tout au long du lycée. Il a accepté de les partager ici, en y apportant des indications précieuses pour nous faciliter leur utilisation « clé en main ».
Jean-Louis Marcia
© APMEP Décembre 2021
⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅♦⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅
Introduction
Les nouveaux programmes de 2019 du lycée donnent une place importante à la programmation. Cette composante est essentielle dans l’activité scientifique et, pour certains élèves, elle peut être source de réconciliation avec les mathématiques.
Il y a quelques années, j’ai entrepris une collaboration avec mes collègues de SVT sur les notions de dérive génétique et de sélection naturelle. Au départ, c’est avec le tableur que nous avons tenté de simuler ces phénomènes. Il est ressorti assez clairement que la simulation contribue largement à leur compréhension auprès des élèves. La programmation en langage Python s’est ensuite imposée peu à peu. Cette expérience a fait l’objet d’un travail au sein du groupe Maths/SVT de l’IREM Paris Nord ![]() .
.
J’ai ainsi élaboré des activités1 qui peuvent être traitées comme un fil rouge à suivre tout au long du cycle du lycée. La simulation, permettant de développer les compétences en algorithmique, y prend naturellement sa place, tout en donnant l’occasion de travailler également certains points mathématiques (suites numériques, lois binomiale, géométrique et des grands nombres, fluctuation d’échantillonnage, conditionnement et indépendance avec des arbres pondérés et la formule des probabilités totales).
Dans cet article, je vous propose de parler de l’activité centrale qui porte sur le phénomène de dérive génétique abordé en classe de Seconde en SVT et qui peut être analysé en spécialité mathématiques de Terminale ou en mathématiques complémentaires.
La dérive génétique en classe de Seconde
Un peu de génétique
Dans un premier temps, le professeur de SVT remobilise le vocabulaire de génétique et aborde la notion de reproduction sexuée des individus au sein d’une population.
Dans les cas simples, un gène peut prendre deux formes (ou allèles) A et a. Chaque gène se trouvant en deux exemplaires, un individu peut donc présenter l’un des trois génotypes suivants : A//A, A//a ou a//a. L’enfant hérite d’un allèle de chacun de ses parents, chaque allèle étant transmis au hasard (figure 1).
Ainsi par exemple, si le génotype du père est A//A et celui de la mère A//a, alors le génotype de l’enfant peut être A//A ou A//a.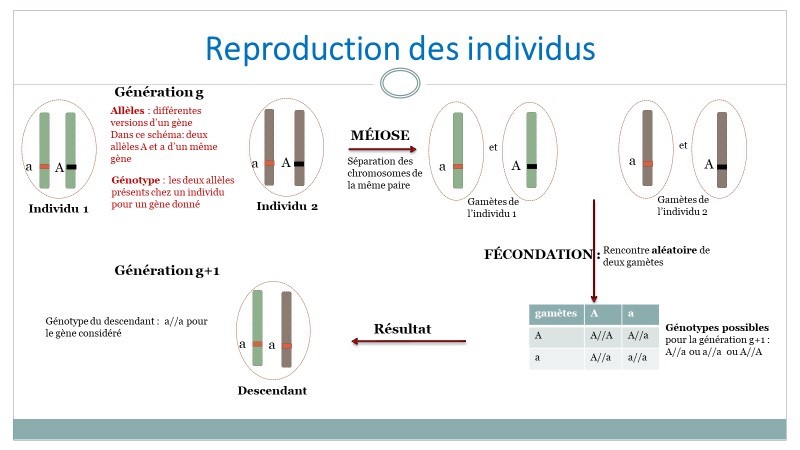
Figure 1. Inspirée du diaporama du parcours Magistère DGESCO [1].
Les couples de la génération \(g\) vont engendrer les individus de la génération \(g + 1\) (figure 2).
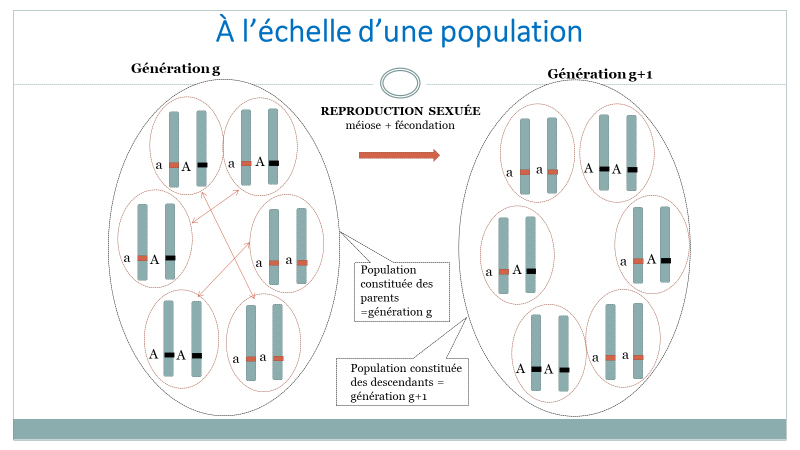
Figure 2. Inspirée du diaporama du parcours Magistère DGESCO [1].
L’objectif est d’étudier l’évolution des fréquences des différents allèles ou des différents génotypes dans la population au cours des générations.
Mise en situation
Afin de fixer les idées avant de se lancer dans la simulation, on présente aux élèves une situation pseudo-concrète (figure 3).
On imagine donc une espèce de tortues dont la carapace a trois couleurs possibles : marron, verte ou beige.
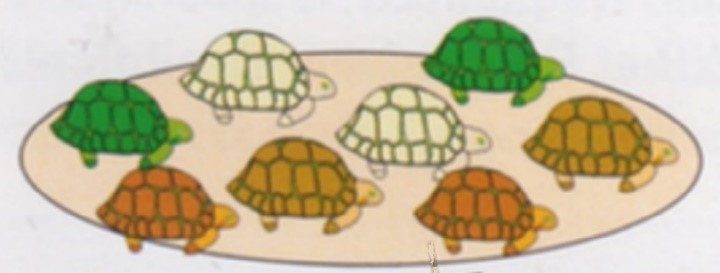
Figure 3. Une population de tortues [2].
.
Le gène contrôlant la couleur de la carapace existe sous deux versions : l’allèle « m » responsable de la couleur marron et l’allèle « v » responsable de la couleur verte.
Ces allèles sont codominants : le génotype m//m révèle la couleur marron, le génotype m//v révèle la couleur beige et le génotype v//v révèle la couleur verte. On dit qu’il y a trois phénotypes possibles.
On peut fixer la taille de la population et la répartition des différents génotypes puis se poser la question : « Comment vont évoluer les fréquences alléliques et génotypiques de cette population au cours des générations ? ».
Vers la simulation
Dans un second temps, on peut envisager la simulation dans le cadre des SNT2 ou de l’AP3 de mathématiques. Pour cela, on ne peut se passer d’une phase indispensable : la modélisation.
Il faut mettre en place des hypothèses de travail et voir avec quels outils il est possible de modéliser une population d’individus et leur reproduction sexuée. Ce travail peut être fait en coanimation, mais surtout avec la collaboration des élèves, quitte à leur suggérer les différents éléments.
Voici donc les hypothèses de travail qui peuvent être mises en place avant d’aborder la simulation.
-
Chaque individu est assimilé à son génotype.
-
Dans un premier temps, on suppose qu’il n’y a pas de mutation au cours des générations, ni de sélection naturelle, ni de migration et que les appariements se font aléatoirement.
-
On considère que la fréquence des allèles dans la population ne dépend pas du sexe des individus. Les couples seront donc formés par le choix aléatoire de deux individus de cette population.
-
On travaille avec une population à effectif constant au cours des générations. Chaque couple engendre donc deux descendants sans chevauchement entre générations.
Reste ensuite à dévoiler aux élèves la manière dont on peut traduire un génotype avec le langage Python. On pourrait choisir d’utiliser une chaîne de caractères comme ’mv’ pour le génotype m//v mais, puisque qu’à partir de la classe de Première les listes font partie des compétences à acquérir en algorithmique, il apparaît plus approprié de traduire ce génotype à l’aide de la liste [’m’,’v’], même si l’écriture est plus compliquée. Il faut de toute façon, expliquer aux élèves que cet ordre imposé par l’objet liste (ou chaîne de caractère) ne créera pas de biais dans la simulation, à condition de signaler que les listes [’m’,’v’] et [’v’,’m’] renverront au même génotype.
On peut soumettre aux élèves le schéma ci-dessous qui rendra la situation plus claire.
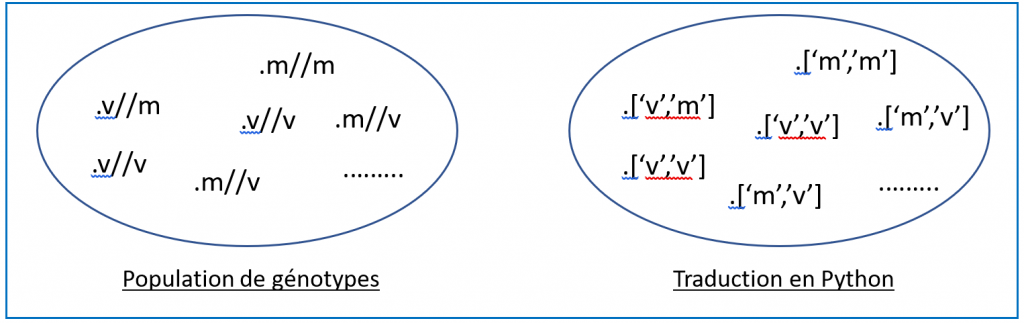
Figure 4. Modélisation.
Le programme Python
Il faut bien rappeler aux élèves que l’objectif du programme est d’afficher, dans un premier temps, le graphique représentant l’évolution des fréquences alléliques au cours des générations.
Pour rendre sa conception et son écriture plus aisées, on met en place trois fonctions (figure 5) qui seront rappelées dans le corps du programme.
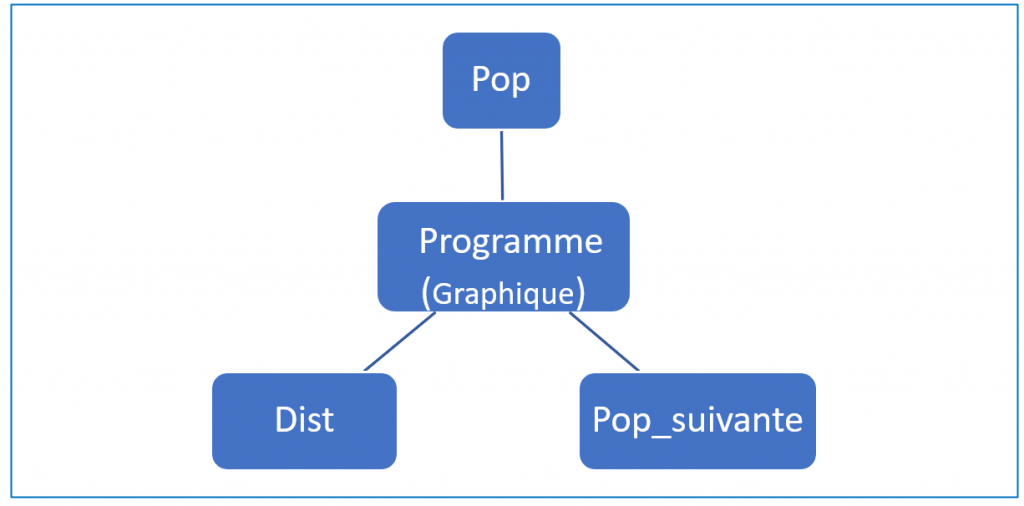
Figure 5. Schéma fonctionnel du programme.
La fonction Pop a pour rôle de générer au hasard une population de taille \(2n\) où \(n\) représente le nombre de couples.
| Fonction Pop |
from random import * def Pop(n) :U = [’m’,’v’] P = [] for i in range(1,2*n+1) :I = [choice(U),choice(U)]P.append(I) |
On utilise ici une urne notée U dont le contenu peut être modifié pour régler la probabilité du choix des allèles. L’utilisation d’un cadre de commentaires en vis-à-vis du texte de la fonction, permet d’aider les élèves à comprendre son aspect algorithmique et de s’approprier les nouveautés du langage comme ici la fonction choice et la méthode append.
D’autre part, il est intéressant qu’ils puissent exécuter la fonction indépendamment du programme pour vérifier s’ils ont bien compris son rôle.
La fonction Dist renvoie une liste contenant la fréquence des allèles ’m’ et ’v’ dans la population.
| Fonction Dist |
def Dist(P) :N_m = 0 N_v = 0 for I in P :N_m = N_m+I.count(’m’)N_v = N_v+I.count(’v’) |
Les élèves pourront constater que l’instruction for s’utilise également pour une liste d’éléments autres que des entiers, ce qui se révèle très pratique ici.
La mise en place de compteurs comme N_m et N_v n’est pas encore acquise par les élèves. C’est donc l’occasion de réexpliquer leur fonctionnement, et d’introduire les méthodes count et len4 qui rendent l’écriture de l’algorithme plus efficace.
On pourra là encore faire appliquer par les élèves cette fonction à la population créée précédemment et indépendamment du programme.
La fonction Pop_suivante constitue l’élément central du programme.
Elle renvoie la génération des descendants créés à partir des couples d’individus d’une population. On a fait ici le choix de constituer ces couples en procédant à des tirages sans remise et en imposant à chaque individu de se reproduire pour générer deux descendants. On peut évidemment faire un tout autre choix, en autorisant par exemple l’autofécondation et la reproduction croisée entre plusieurs individus, ce qui revient à effectuer des tirages avec remise.
| Fonction Pop_suivante |
def Pop_suivante(P) :P_suivant = [] while P!=[] :I_1 = choice(P)P.remove(I_1)I_2 = choice(P)P.remove(I_2)E_1 = [choice(I_1),choice(I_2)]E_2 = [choice(I_1),choice(I_2)]P_suivant.append(E_1)P_suivant.append(E_2) |
D’un point de vue algorithmique, on découvre la méthode remove5 qui assure le choix sans remise. L’intérêt de cette fonction se situe surtout au niveau biologique, où les mécanismes de la reproduction sexuée jouent complètement leur rôle, ce qui permet à l’élève de mieux les comprendre : l’algorithme vient alors au secours de la biologie !
Enfin, et toujours indépendamment du programme, l’application de cette fonction à la population précédente, suivi de la fonction Dist pour la nouvelle génération, permet de constater l’évolution des fréquences alléliques d’une génération à la suivante.
Pour finir, ces trois fonctions sont rappelées dans le corps du programme (figure 9) dont le rôle est d’afficher le graphique retraçant l’évolution des fréquences alléliques au cours des générations. L’instruction input invite l’utilisateur à saisir les valeurs du nombre de couples \(n\) et du nombre de générations \(g\).
Enfin la fréquence de l’allèle ’v’ est représentée en vert et celle de l’allèle ’m’ en mauve (plutôt que marron pour des raisons purement esthétiques).
Suivant le niveau des élèves sur la pratique du langage Python, on peut présenter le travail en les laissant compléter les parties manquantes.
Il faut remarquer que les points de la représentation graphique sont créés à l’intérieur de la boucle for, ce qui, pour le niveau de la classe de Seconde, est approprié. À partir de la classe de Première on pourra utiliser les listes pour une exécution plus efficace.
import mathplotlib.pyplot as pltplt.axis([-0.1,g,0,1])P = Pop(n)for i in range(1,g+1) :P = Pop_suivante(P)L = Dist(P)plt.plot(i,L[0],’m.’)plt.plot(i,L[1],’gx’) |
Figure 6. Programme permettant la représentation graphique des fréquences alléliques.
Exécution du programme
À la fin de l’activité, on demande aux élèves d’exécuter le programme en fixant le nombre de générations à 100 et en faisant varier la taille \(n\) de la population. Les graphiques obtenus sont à consigner dans un fichier texte et les élèves doivent ensuite définir eux-mêmes la notion de dérive génétique.
Cette activité a été testée dans une classe de Seconde l’an dernier et on a pu constater que l’objectif visé était atteint. Outre l’apprentissage des outils algorithmiques, le professeur de SVT a pu noter que l’utilisation de ce programme Python apportait aux élèves une plus-value à la compréhension de cette notion de dérive génétique.
Si les termes utilisés par les élèves ont manqué de précisions, l’idée centrale de la notion de dérive génétique a été émise, à savoir que les fréquences alléliques dans la population sont modifiées aléatoirement au cours des générations et que la variation est d’autant plus grande que la taille de la population est faible (figures 7 et 8).
Sur ce dernier point, il faut bien faire remarquer aux élèves que la stabilité des fréquences lorsque la taille de la population est grande n’est qu’apparente. Même avec un effectif conséquent d’environ 1000 individus, les fréquences globalement stables sur une centaine de générations finissent par diverger et par aboutir à la disparition d’un des allèles, sur un temps d’observation suffisamment long (figure 9).
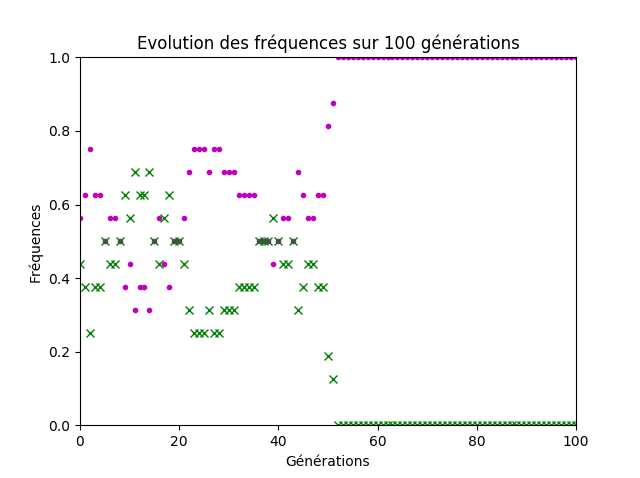
Figure 7. Quatre couples d’individus.
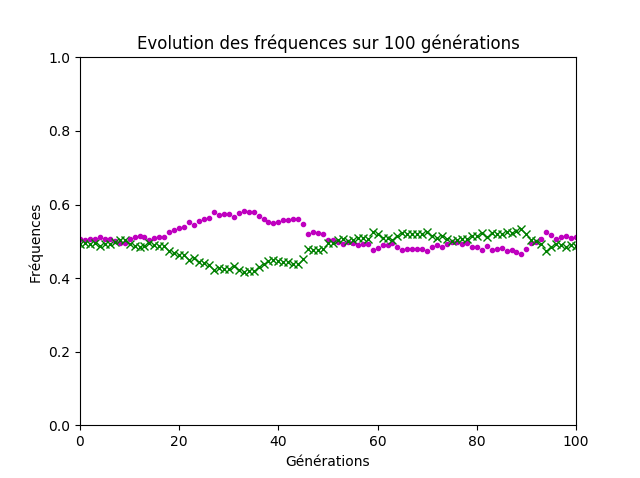
Figure 8. Cinq-cents couples d’individus.
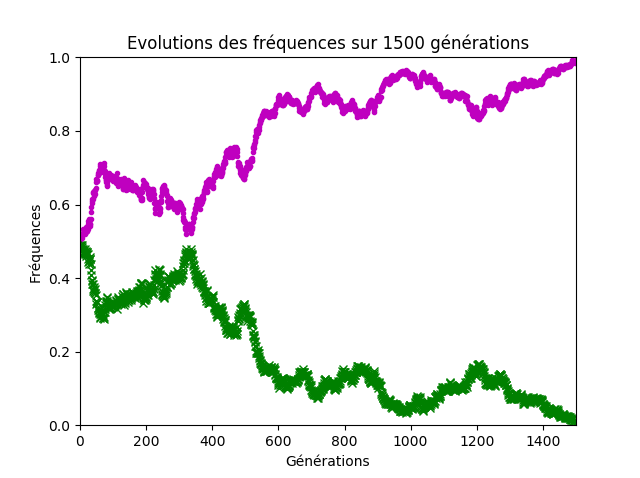
Figure 9. Cinq-cents couples d’individus.
On peut penser que, quelle que soit la taille de la population, cette divergence et l’extinction d’un des allèles finira par arriver à condition d’attendre suffisamment longtemps. Mais cela reste à démontrer !
En enseignement scientifique de Terminale, les élèves étudieront le modèle de Hardy-Weinberg qui stipule que, pour une population idéale, en particulier de taille infinie, les fréquences alléliques sont stables au cours des générations. On peut envisager la démonstration de ce modèle dès la Première en spécialité mathématique après le chapitre relatif aux probabilités conditionnelle et à l’indépendance.
Il faudra bien rappeler aux élèves que dans la pratique, même si la population est de grande taille, elle est malgré tout soumise à la dérive génétique qui pourra devenir importante si la période étudiée est grande.
Analyse mathématique de la dérive génétique en Terminale
Les graphiques obtenus après l’exécution du programme Python caractérisent le phénomène de dérive génétique. Cette variation des fréquences alléliques fait penser à une marche aléatoire. Dans le cadre de la spécialité ou des mathématiques complémentaires, on pourrait proposer aux élèves d’analyser ce phénomène de dérive génétique comme application de la loi binomiale et de la fluctuation d’échantillonnage.
Notons \(f_{g}\) la fréquence d’un des allèles étudiés dans une population de taille \(N\) (pair) à une génération \(g\). Pour simplifier, on considère que la génération \(g + 1\) s’obtient en effectuant \(2N\) répétitions indépendantes (2 allèles par individu) du choix au hasard d’un allèle dans la génération \(g\).
Cette indépendance, toute relative en général, est fondée si on autorise l’autofécondation et la reproduction croisée entre plusieurs individus. Ce qui revient à effectuer des tirages avec remise pour former les couples.
La génération \(g\) joue le rôle d’urne dans laquelle se font ces choix. Pour chaque répétition, la probabilité du succès correspond à la fréquence de l’allèle considéré dans la population, c’est-à-dire \(f_{g}\).
La génération \(g+ 1\) quant à elle joue le rôle d’échantillon aléatoire de taille \(2N\).
Si on note \(X\) la variable aléatoire comptant le nombre de succès de cet échantillon, c’est à dire l’effectif de l’allèle considéré à la génération \(g
+ 1\), \(X\) suit alors la loi binomiale de paramètres \(2N\) et \(f_{g}\).
La fréquence \(f_{g+1}\) de cet allèle vaut donc \(\dfrac{X}{2N}\), et en tant que fréquence aléatoire, est soumise à la fluctuation d’échantillonnage.
Son écart-type \(\sigma\) est donné par \(\sqrt{\dfrac{f_{g}\left(1-f_{g}\right)}{2N}}\) (loi de Bernoulli de paramètre \(f_{g}\)) et détermine ainsi (pour \(N\) grand) l’intervalle de fluctuation à 95 %, soit environ \(\left[f_{g}-2\sigma~ ;~f_{g}+2\sigma\right]\).
Ensuite, cette nouvelle génération jouera elle-même le rôle d’urne pour former la génération \(g+2\), et ainsi de suite.
Pour se conformer aux nouveaux programmes de 2019, on peut utiliser l’inégalité de concentration afin de déterminer la taille de la population minimale pour que l’écart \(\left\vert f_{g+1}-f_{g} \right\vert\) ne dépasse pas 0,01 par exemple, au risque de 5 %.
On a : \(P \left(\left\vert f_{g+1}-f_{g} \right\vert \geqslant {0.01}\right)
\leqslant \dfrac{f_{g}(1-f_{g})}{2N \times 10^{-4}}\), avec \(f_{g}(1-f_{g})
\leqslant \dfrac{1}{4}\). Il suffit de prendre \(N \geqslant {25000}\).
On peut noter que l’intervalle de fluctuation à 95 % est plus rentable et donne \(N \geqslant
{5000}\).
Pour finir, voici une façon (figure 10) de synthétiser le processus développé ci-dessus et d’expliquer qu’à chaque génération la fréquence allélique considérée est soumise à une fluctuation qui est d’autant plus faible que la taille de la population est grande, et inversement, d’autant plus grande que la taille est faible.
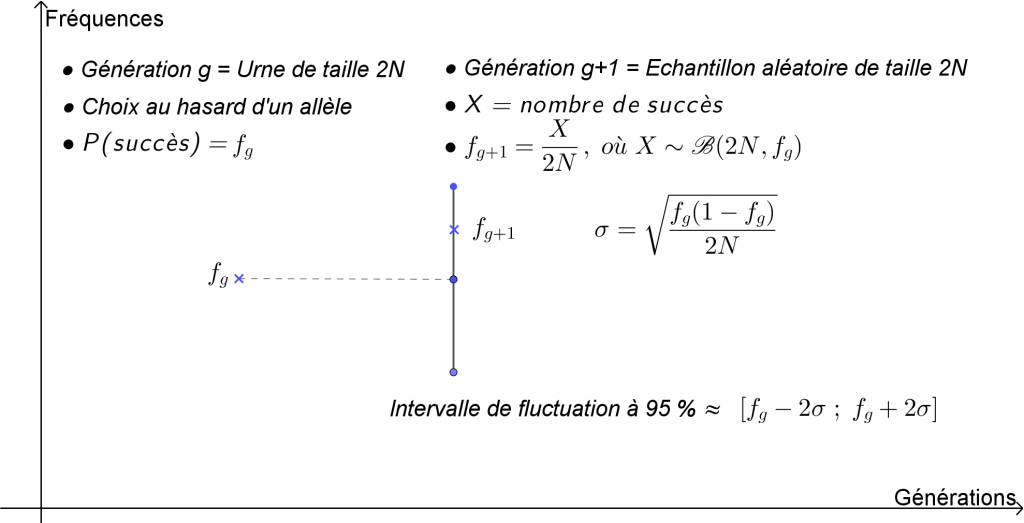
Figure 10. Loi binomiale et intervalle de fluctuation.
Conclusion
Les activités développées dans cet article sont fondées sur des hypothèses de travail. Leurs résultats devront ensuite être confrontés à la réalité pour les valider ou les réfuter en s’interrogeant sur leurs limites. On comprend que la simulation est un apport à la compréhension de ces phénomènes biologiques. Comme toute simulation, elle impose une phase de modélisation avec son lot d’hypothèses, ce qui est un apprentissage certes délicat mais fondamental.
|
La simulation fait également partie de l’activité mathématique : elle permet de faire des conjectures, voire de répondre à certaines questions. |
Partager cela avec nos élèves n’est sans doute pas inutile même s’il est vrai que le temps imparti pour traiter les programmes rend l’exercice difficile, mais pas impossible.
L’étude des autres forces évolutives ainsi que les autres phénomènes liés à ces différente formes, telles que mutations, sélection naturelle et choix du partenaire, sont proposées en complément dans la revue numérique ![]() . Vous y trouverez en particulier le modèle de Hardy-Weinberg au programme de l’enseignement scientifique de Terminale mais qui, sur le plan mathématique, peut être abordé dès la Première.
. Vous y trouverez en particulier le modèle de Hardy-Weinberg au programme de l’enseignement scientifique de Terminale mais qui, sur le plan mathématique, peut être abordé dès la Première.
Références
-
Les mardis de l’enseignement scientifique. Diaporama du parcours Magistère DGESCO. 2019-2020.
-
M Hatty. Génétique moléculaire et évolution. 2008, p. 325.
⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅♦⋅⋅⋅⋅⋅⋅⋅⋅⋅⋅
Jean-Louis Marcia est professeur de mathématiques au lycée Pablo Picasso de Fontenay-sous-Bois et membre du groupe de travail Maths/SVT de l’IREM Paris Nord
.
-
Vous trouverez toutes les activités proposées dans cet article ici
.↩︎ -
Sciences Numériques et Technologiques.↩︎
-
Accompagnement Personnalisé.↩︎
-
La méthode
countrenvoie le nombre d’occurrences de l’élément dans la liste et la méthodelenle nombre d’éléments de la liste.↩︎ -
La méthode
removeretire l’élément de la liste.↩︎